
Deprecated: Return type of TagFilterNodeIterator::current() should either be compatible with Iterator::current(): mixed, or the #[\ReturnTypeWillChange] attribute should be used to temporarily suppress the notice in /home2/naomindc/public_html/stylengineer/wp-content/plugins/easy-table-of-contents/includes/vendor/ultimate-web-scraper/tag_filter.php on line 1149
Deprecated: Return type of TagFilterNodeIterator::next() should either be compatible with Iterator::next(): void, or the #[\ReturnTypeWillChange] attribute should be used to temporarily suppress the notice in /home2/naomindc/public_html/stylengineer/wp-content/plugins/easy-table-of-contents/includes/vendor/ultimate-web-scraper/tag_filter.php on line 1159
Deprecated: Return type of TagFilterNodeIterator::key() should either be compatible with Iterator::key(): mixed, or the #[\ReturnTypeWillChange] attribute should be used to temporarily suppress the notice in /home2/naomindc/public_html/stylengineer/wp-content/plugins/easy-table-of-contents/includes/vendor/ultimate-web-scraper/tag_filter.php on line 1154
Deprecated: Return type of TagFilterNodeIterator::valid() should either be compatible with Iterator::valid(): bool, or the #[\ReturnTypeWillChange] attribute should be used to temporarily suppress the notice in /home2/naomindc/public_html/stylengineer/wp-content/plugins/easy-table-of-contents/includes/vendor/ultimate-web-scraper/tag_filter.php on line 1144
Deprecated: Return type of TagFilterNodeIterator::rewind() should either be compatible with Iterator::rewind(): void, or the #[\ReturnTypeWillChange] attribute should be used to temporarily suppress the notice in /home2/naomindc/public_html/stylengineer/wp-content/plugins/easy-table-of-contents/includes/vendor/ultimate-web-scraper/tag_filter.php on line 1139
Deprecated: Return type of TagFilterNodeIterator::count() should either be compatible with Countable::count(): int, or the #[\ReturnTypeWillChange] attribute should be used to temporarily suppress the notice in /home2/naomindc/public_html/stylengineer/wp-content/plugins/easy-table-of-contents/includes/vendor/ultimate-web-scraper/tag_filter.php on line 1164
Python是近期非常熱門的程式語言,其簡易程式語法搭配模組套件例如:BeautifulSoup,DataFrame,Pandas…就能完成強大的文字處理與文字解析,就連Word的docx附檔名的檔案都能輕鬆讀取。
以下示範使用Python搭配編輯器Jupyter notebook讀取Word .docx檔案教學
★Python Word .docx讀檔教學:
STEP1:開啟Poweshell下載docx module
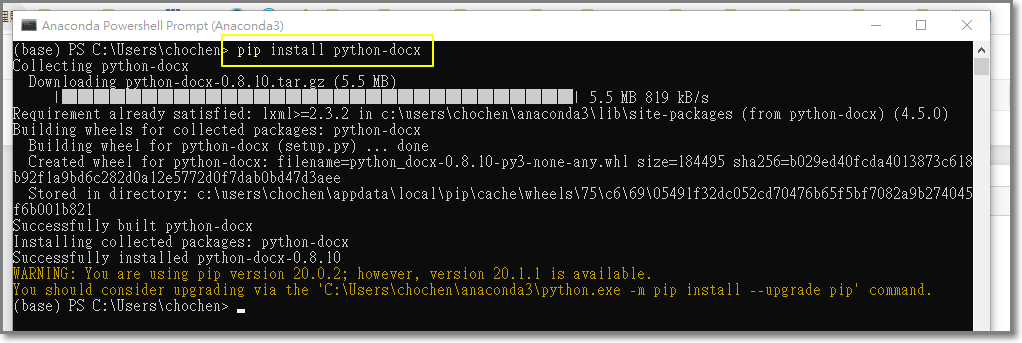
輸入”pip install python-docx”
STEP2:Jupyter notebook 程式碼範例
(1)基本讀檔:
import docx
file=docx.Document(r"your_file_name.docx")
print(type(file)) #'docx.document.Document'
for i in file.paragraphs:
print(i.text)
- docx.Document():將docx檔案讀成Documents物件
- Documents物件.paragraphs:將檔案一行一行轉換成元素是paragraph的list
- paragraph.list:將一段一段的paragraph讀成文字
(2) Regex Expression文字處理:
搭配re module就可以使用regular expression做字串解析&字串比對
import docx
import re
file=docx.Document(r"yout_file_name.docx")
count = 0
for i in file.paragraphs:
if re.match(r'\([a-z]\)',i.text): #抓到(a),(b),(c)..(z)開頭行
print('match!',i.text)
count+=1
print(count)




